20 KiB
JCS-pub(云际存储公共基础设施+开箱即用云际存储客户端)
项目简介
云际存储是基于云际对等协作机制,纳管多个云的存储资源,为用户提供统一数据存储服务的一种存储服务模式。其核心理念是强调各个云的对等独立地位,通过非侵入方式联接多个云的存储资源;强调云际协作,综合运用各个云的存算网资源,提供高质量存储服务。
本项目旨在将云际存储公共基础设施化,使个人及企业可低门槛使用高效的云际存储服务(安装开箱即用云际存储客户端即可,无需关注其他组件的部署),同时支持用户灵活便捷定制云际存储的功能细节。
项目演化路径

特性
1、数据迁移能力
- 跨云迁移支持:支持用户在多个云存储服务间迁移数据
- 策略化迁移引擎
- 筛选条件:按文件大小、后缀类型、目录路径定向迁移
- 调度控制:设置迁移时间窗口
- 迁移后操作:可选保留或删除原数据
- 迁移效率优化:通过云际存储公共基础设施提高迁移效率,降低用户流量成本
2、跨云存储数据
- 统一多云存储视图:支持数据分散存储至多个云平台,并为用户提供统一数据视图,屏蔽底层多云复杂性
- 多级容灾冗余方案:提供云级容灾能力,支持纠删码、多副本、混合冗余(纠删码+多副本)等多种冗余方案
- 自适应冗余策略
- 冗余方案:自定义副本数、EC编码块数及算法
- 数据放置:各副本或编码块放置策略
- 跨云操作指令集:支持定制化指令,包括:上传、下载、随机读、跨云调度、跨云修复等
- 多种数据访问模式
- REST API
- 命令行
- FUSE
- 访问效率优化:通过云际存储公共基础设施,提高跨云数据访问效率,降低用户流量成本
3、本地+多云混合存储数据
- 统一混合存储视图:支持数据分散存储于本地文件系统及多个远端云平台,并为用户提供统一数据视图,屏蔽底层多云复杂性
- 智能数据协同策略提供多种本地文件系统与远端云存储服务间的数据协同策略
- 数据筛选机制:按文件大小、目录路径、后缀类型动态筛选需同步至远端的数据
- 本地留存机制:可配置远端数据是否在本地保留副本
- 双向同步策略:可分别配置本地到远端、远端到本地的同步策略
- 协同效率优化:通过云际存储公共基础设施,提高本地与远端协同的效率并降低用户流量费用
- 多种数据访问模式
- REST API
- 命令行
- FUSE
4、开箱即用
- 下载安装客户端即可使用。
5、云际存储公共基础设施
- 统一混合存储视图:支持数据分散于本地文件系统和多个远端云平台,并为用户提供统一数据视图,屏蔽底层多云复杂性
- 双模运行架构:
- 独立运行模式:客户端可完全离线操作,不依赖其他服务
- 基础设施连接模式:接入公共基础设施后运行(可提高数据传输效率,降低用户流量费用)
- 开源公共基础设施:
- 任何用户可自主部署公共基础设施,或接入现有公共基础设施
- 免费公共基础设施:
- 请发邮件至
song-jc@foxmail.com领取账号密码和证书,申请流程如下图。
- 请发邮件至

架构图
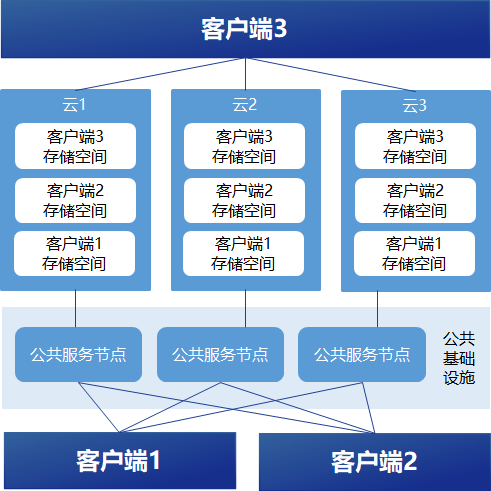
1、云存储空间
- 使用云际存储客户端前,用户需自行准备云存储空间。云存储空间主要指对象存储服务的桶和文件存储服务的目录。可使用用户在公有云开通的云存储服务,也可以使用用户私有的云存储服务。
- 主流的公有云存储服务注册教程见链接:跳转
2、云际存储公共基础设施
- 公共基础设施包含若干代理节点,它们可以根据客户端的请求,与客户端协同完成跨云数据迁移、数据上传、数据下载等访问操作,并可通过数据传输路径优化、数据并发访问等技术提高数据访问效率,同时降低客户端的流量开销并避免客户端成为数据传输瓶颈。
3、云际存储客户端
- 云际存储客户端部署在用户的服务器上,充当数据服务网关和元数据管理节点的角色。
- 用户通过客户端提供的各类方式管理用户自由的云存储空间中的数据。
- 用户数据的元数据和其云存储空间的鉴权方式仅保留在用户自己运维的客户端上,代理节点需访问客户的云存储空间时由客户端为其临时赋权。
安装
1、第三方组件准备
以下组件需要自行安装:
MySQL:8.0版本以上,创建好JCS客户端使用的账户和数据库
2、Docker安装(推荐)
目前仅有JCS客户端提供了Docker镜像,jcsctl工具需要使用提前编译的可执行文件,点此下载
获取镜像
docker pull jcs:latest
如果你已经准备好了JCS客户端的配置文件和证书文件,那么在运行容器前只需要将包含这些文件的目录通过-v参数挂载到容器里即可,并在运行容器时使用-c来指定配置文件的位置(容器中的位置)。
如果你没有提前准备好配置文件,想要通过JCS客户端的init命令来生成,那么也需要使用-v参数将宿主机 的一个目录挂载到容器内,并在之后的生成配置的过程中将配置文件和证书文件保存到这个目录。
完整的执行命令大概如下格式:
# 假设配置文件在宿主机的/etc/jcsconfs目录下
docker run -v /etc/jcsconfs:/opt/confs \
jcs serve -c /opt/confs/config.json # 注意配置文件路径是容器内的路径
3、源码编译安装
编译前你需要准备好:
Go:1.23及以上的版本mage:一个类似于makefile的工具,用于运行编译命令,官方仓库:仓库地址
安装好上述依赖后,将本项目的仓库克隆到本地,然后在仓库目录中打开终端,输入以下命令进行编译:
mage bin
命令执行结束后会在仓库目录内生成一个build文件夹,里面包含编译产生的所有的可执行文件,文件包括:
jcs:JCS客户端程序jcsctl:客户端的命令行工具,可以将其加入到PATH环境变量中,方便使用coordinator:JCS系统的协调节点程序,如果只是使用公共的JCS系统则可以忽略这个文件hub:JCS系统的枢纽节点程序,作用同上
4、可执行文件安装
选择适合你环境的程序下载并解压即可使用:下载地址
使用指南
1、生成配置文件
使用JCS客户端的init命令进入配置流程,按照命令提示填写相关内容。注意:如果将要使用Docker镜像来运行JCS客户端,配置里的路径都要是容器里的路径。
命令执行结束后,一共将生成以下几个文件:
config.json:客户端程序的完整配置文件ca_cert.pem:HTTP服务使用的根证书ca_key.pem:HTTP服务的根秘钥,需要自己额外保管server_cert.pem、server_key.pem:使用根秘钥签发的服务端证书client_cert.pem、client_key.pem:使用根秘钥签发的客户端证书,jcsctl工具或第三方程序使用
除了ca_key.pem文件外,其他文件在客户端运行时都会使用到。
配置文件的字段介绍如下:
{
"hubRPC": {
"rootCA": "" // 与Hub服务通信时使用的根证书的路径
},
"coordinatorRPC": {
"address": "127.0.0.1:5009", // Coordinator服务的地址
"rootCA": "" // 与Coordinator服务通信时使用的根证书的路径,一般与Hub服务的根证书相同
},
"logger": {
"output": "stdout", // 日志的输出方式,可选值为stdout、file
"outputFileName": "client", // 日志文件的名称,仅当output为file时有效
"outputDirectory": "log", // 日志文件的目录,仅当output为file时有效
"level": "debug" // 日志的级别,可选值为debug、info、warn、error
},
"db": {
"address": "127.0.0.1:3306", // MySQL数据库的地址
"account": "root", // 数据库的账号
"password": "123456", // 数据库的密码
"databaseName": "cloudream" // 数据库的名称
},
"connectivity": {
"testInterval": 300 // 测试与Hub的连通性的时间间隔,单位为秒
},
"downloader": {
"maxStripCacheCount": 100, // 在读取文件时最多缓存的EC条带的数量
"ecStripPrefetchCount": 1 // 在进行读取操作时预取EC条带的数量
},
"downloadStrategy": {
"highLatencyHub": 35 // 测试到Hub的延迟时超过这个值则认为这个Hub是高延迟的,单位为ms
},
"tickTock": {
"ecFileSizeThreshold": 5242880, // 存储的文件超过这个大小时才使用EC编码,单位为字节
"accessStatHistoryWeight": 0.8 // 更新文件当天的访问量时,前一天的访问量在计算中所占的权重,取值范围为0~1
},
"http": {
"enabled": true, // 是否开启HTTP服务
"listen": "127.0.0.1:7890", // HTTP服务的监听地址
"rootCA": "", // 根证书的路径
"serverCert": "", // 服务器证书的路径
"serverKey": "", // 服务器私钥的路径
"clientCerts": [], // 通过根证书签发的客户端证书列表
"maxBodySize": 5242880 // HTTP请求的最大Body大小,单位为字节
},
"mount": {
"enabled": false, // 是否开启FUSE挂载
"mountPoint": "", // FUSE挂载dir的路径
"gid": 0, // 挂载目录中文件和文件夹的gid
"uid": 0, // 挂载目录中文件和文件夹的uid
"dataDir": "", // 文件缓存目录
"metaDir": "", // 文件元数据目录
"maxCacheSize": 0, // 缓存目录的最大大小,单位为字节,0表示不限制。这个限制不是硬性的、实时的。
"attrTimeout": "10s", // 操作系统缓存文件属性的时间
"uploadPendingTime": "30s", // 挂载目录里的文件被修改后,等待多少时间才开始从缓存目录上传JCS
"cacheActiveTime": "1m", // 加载到内存中的文件数据的有效时间,超过这个时间仅仅是清除内存中的缓存数据
"cacheExpireTime": "1m", // 从内存中被清除后,缓存文件在硬盘上的保留时间。仅对已经被完全上传到JCS的文件有效。
"scanDataDirInterval": "10m" // 扫描缓存目录的时间间隔
},
"accessToken": {
"account": "", // 登录公共JCS系统的账号
"password": "" // 登录公共JCS系统的密码
}
}
注意:如果要基于这个文件手动填写配置文件,则要删除所有的注释,因为JSON不支持注释。
2、命令行
jcsctl是JCS客户端的命令行工具,使用它可以管理JCS客户端的内容。
jcsctl与JCS客户端通信时需要使用证书进行鉴权,这些证书在JCS客户端的初始化时产生,一共需要ca_cert.pem、client_cert.pem、client_key.pem三个文件。jcsctl启动时会按以下规则去查找这些文件:
- 通过命令行参数
--ca、--cert、--key指定 - jcsctl自身所在目录
jcsctl默认使用https://127.0.0.1:7890地址去尝试连接客户端,如果客户端地址不同,则可以使用--endpoint设置地址。
3、API
见文档 跳转
测试评估
定制冗余策略
对象的冗余策略对于读写过程的影响体现在代码里的方方面面,建议你在实现自己的冗余策略时参考已有的策略多找多看,防止遗漏。
接下来的行文是按照便于理解的顺序来编写,不一定适合实际实现,建议通读之后再选择合适的切入点动手。
1、冗余变化
对象刚上传时它是以完整文件的形式存在某个存储空间的,它的冗余策略是None,即没有冗余。对象冗余策略的变化是由JCS客户端的一个定时任务ChangeRedundancy进行,它会在每天凌晨的触发。冗余变化大体分为两个步骤:
- 选择冗余策略:根据一定规则选择对象的冗余策略,比如对象大小等。并不是只有没有冗余的对象才能变化,有需要的话你可以让对象在不同的冗余方式之间改变。
- 执行变化:根据事先选择的策略和当前对象的策略生成执行计划并执行。如果需要定制计划指令,请查看后续的定制指令的说明。
具体可参考gitlink.org.cn/cloudream/jcs-pub/client/internal/ticktock包中change_redundancy.go和redundancy_recover.go部分的代码。
2、冗余收缩
冗余收缩采用模拟退火算法从容灾度、冗余度、访问效率三个方面来调整对象的冗余文件的数量、分布,目前仅支持多副本和纠删码的收缩。
这部分的功能不是必须实现的,有需要可以参考gitlink.org.cn/cloudream/jcs-pub/client/internal/ticktock包中redundancy_shrink.go部分的代码。
3、对象下载
涉及到需要下载对象的功能(不仅仅是HTTP的下载对象功能),都需要调整代码以支持新的冗余策略。下载过程分为选择下载策略和执行策略两部分。
选择策略的代码相对集中,在gitlink.org.cn/cloudream/jcs-pub/client/internal/downloader/strategy包中,而执行策略的代码则除了gitlink.org.cn/cloudream/jcs-pub/client/internal/downloader包以外,还在项目中有所分布,建议善用搜索功能避免遗漏。
定制指令
当前项目中大部分已实现指令可在项目的gitlink.org.cn/cloudream/jcs-pub/common/pkgs/ioswitch2包中找到,可以作为开发过程中的参考。
1、编写指令逻辑
每一个指令都要实现以下接口:
type Op interface {
Execute(ctx *ExecContext, e *Executor) error
String() string
}
String():用于调试时打印指令的内容。Execute(ctx *ExecContext, e *Executor)error:指令的执行逻辑,该函数包含两个参数:ctx:执行指令的上下文,其中的Context字段用于支持中断指令操作,Values则包含执行计划时提供的额外参数,可以通过gitlink.org.cn/cloudream/common/pkgs/ioswitch/exec包中的GetValueByType、SetValueByType等函数修改。e:执行器,可以通过BindVar和PutVar函数来访问内部的变量表,实现数据在不同指令之间的传递。也可以使用gitlink.org.cn/cloudream/common/pkgs/ioswitch/exec中提供的泛型版本的BindVar、BindArray等函数。
当Execute返回的error不为nil时,整个计划会被视为执行失败,所有正在执行的指令都会被中断。
编写指令的过程一般按照以下步骤进行:
- 读取参数:调用参数e的BindVar等函数读取数据。BindVar需要的VarID应该在生成指令时就已经填好,存放在指令自己的某个字段里。
- 处理:根据你的想法编写代码
- 产生结果:调用参数e的PutVar等函数,将处理后的数据放回到变量表中,供后续的指令使用。同理,PutVar需要的VarID也应该提前生成好。
如果你理解了模块的工作原理,那完全可以任意编写逻辑。
Put或Bind的数据是用户可自定义的结构体,只需实现下面这个接口:
type VarValue interface {
Clone() VarValue
}
注意:数据在不同指令之间传递时会经历JSON格式的序列化和反序列化过程,因此不要在结构体里放不可被序列化的数据结构。
如果你想要在两个指令间传递一个流(io.ReadCloser),则应该使用模块内置的StreamValue结构体,不要自行定义包含流的结构体,因为流的复制和传递都需要特殊处理,在下一节定义DAG节点时你就能清楚这一点。
当指令的Execute函数返回了nil后,这个指令就执行结束了,而当某个节点上的指令都执行结束,则这个节点上的计划也会结束,因此如果你的指令会产生流,那么建议使用WaitGroup等方式,在产生的流被读取结束后再结束Execute函数。
最后,当你定义好了指令和数据后,记得使用gitlink.org.cn/cloudream/common/pkgs/ioswitch/exec中的UseOp和UseVarValue函数来将它们注册到模块内。
2、编写指令对应DAG节点
ioswitch模块使用DAG来表述一个计划,DAG中的每个节点都对应一条指令,而节点之间的连线则代表它们之间的数据依赖。
自定义节点需要实现下面这个接口:
type Node interface {
Graph() *Graph
SetGraph(graph *Graph)
Env() *NodeEnv
InputStreams() *StreamInputSlots
OutputStreams() *StreamOutputSlots
InputValues() *ValueInputSlots
OutputValues() *ValueOutputSlots
GenerateOp() (exec.Op, error)
}
从接口的定义可以看出:
- 一个节点包含4组Slot,分别是流和值的输入输出Slot。每一个输入Slot代表这个指令需要的外部数据,只允许从一个节点来,而每一个输出Slot代表这个指令会产生的输出,可以送到多个节点去。
- Env代表这个指令将在哪个环境里执行,比如在Driver(发起计划的服务,即JCS客户端)、Hub(代理节点)、Any。大多数指令的Env设置成Any即可,除非你确定这个指令必须在哪个环境执行。
- 最后的GenerateOp函数是计划DAG优化结束后生成指令时被调用的。
推荐嵌入gitlink.org.cn/cloudream/common/pkgs/ioswitch/dag包中的NodeBase结构体,它实现了除GenerateOp以外的其他函数。
3、使用指令
一个计划的生成大体可以分为:编写FromTo、解析FromTo为DAG、优化DAG、根据DAG生成指令几个过程,你可以在前三个阶段增加代码来利用你的指令。
FromTo是用于描述计划的模型,From描述数据从哪来,To描述数据到哪去,解析计划的算法将根据一定规则去生成一个联系From和To的DAG,并最终转化为一系列指令。如果有必要,你可以编写自己的From和To,它们只需满足以下接口:
type From interface {
GetStreamIndex() StreamIndex
}
type To interface {
// To所需要的文件流的范围。具体含义与DataIndex有关系:
// 如果DataIndex == -1,则表示在整个文件的范围。
// 如果DataIndex >= 0,则表示在文件的某个分片的范围。
GetRange() math2.Range
GetStreamIndex() StreamIndex
}
然后在gitlink.org.cn/cloudream/jcs-pub/common/pkgs/ioswitch2/parser/gen的合适位置编写从FromTo到DAG的算法即可。
注意:你根据FromTo生成的DAG的节点应该实现要实现以下接口
type FromNode interface {
dag.Node
GetFrom() ioswitch2.From
Output() dag.StreamOutputSlot
}
type ToNode interface {
dag.Node
GetTo() ioswitch2.To
Input() dag.StreamInputSlot
}
因为部分DAG优化算法需要识别这些信息。
在DAG优化阶段你也可以增加你自己的优化步骤来用到你的指令,一般是通过遍历DAG来找到符合某种模式的一系列指令,然后对这些指令进行变换或者替换,达到减少指令数量或者采用更高效实现的目的。
当你实现好自己的优化步骤后,需要在gitlink.org.cn/cloudream/jcs-pub/common/pkgs/ioswitch2/parser中的Parse函数的合适位置插入调用你的函数的代码,你需要仔细考虑你的步骤与其他步骤之间相互影响。
许可证
MulanPSL v2
开发小组
规划设计:包涵
设计实现:龚西华 宋建聪 任致始 张凯鑫 阚浚晖
指导专家:王意洁
技术咨询:宋建聪(邮箱:song-jc@foxmail.com)